Test the deployment and verify RAG workflow
Understand RAG and use the UI
Now that you’ve verified all services are running, let’s take a look at the UI provided by the implementation.
To access the UI, open any browser and go to the DNS of the ChatQnA Load Balancer: http://chatqna-ingress-xxxxxxx.us-east-2.elb.amazonaws.com (Modify with your chatqna-ingressDNS URL)
In the UI you can see the chatbot interact with it

To verify the UI, go ahead and ask
What was Nike's revenue in 2023?
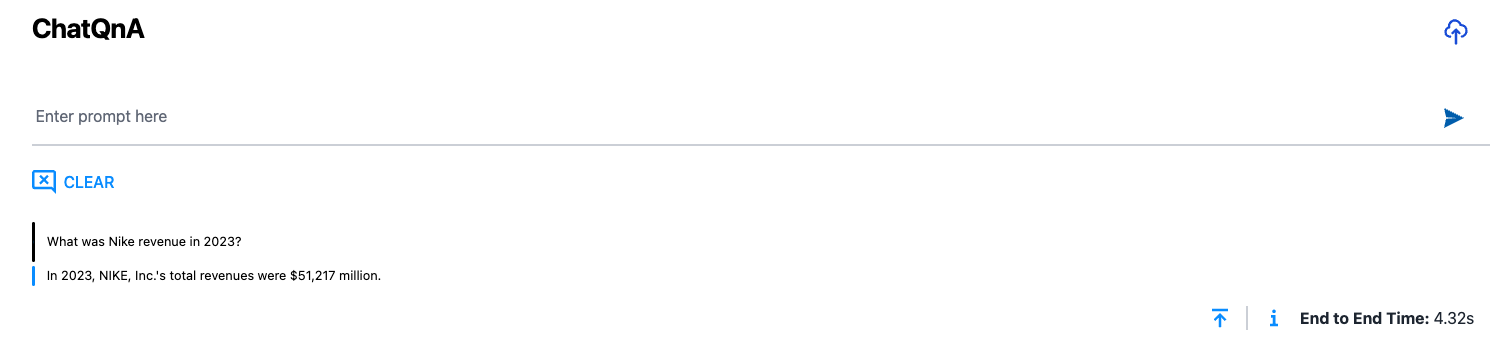
The answer is correct again because we already indexed our knowledge base on the previous step.
Let’s try something different. Will the app be able to answer about OPEA:
What is OPEA?

The answer may vary slightly based on factors like input formatting. For instance, differences in capitalization can sometimes lead to different responses.
Notice that the initial answer provided by the chatbot is outdated or lacks specific information about OPEA. This is because OPEA is a relatively new project and wasn’t part of the dataset used to train the language model. Since most language models are static—they rely on data available at the time of training—they can’t automatically incorporate recent developments or information about new projects like OPEA.
However, RAG offers a solution by enabling real-time context. Through the UI, you’ll see an icon that allows you to upload relevant context information. This action initiates a process where the document is sent to the DataPrep microservice to generate embeddings, and the data is then ingested into the Vector Database.
By uploading a new document or link, you’re effectively expanding the chatbot’s knowledge base to include the latest information, which helps improve the relevance and accuracy of the responses.

The deployment allows you to upload either a file or a site. For this case, use the OPEA site:
- Click on the upload icon to open the right panel
- Click on Paste Link
- Copy/paste the text
https://opea-project.github.io/latest/introduction/index.htmlto the entry box - Click Confirm to start the indexing process
When the indexing completes, you’ll see an icon added below the text box, labeled https://opea-project.github.io/latest/introduction/index.html
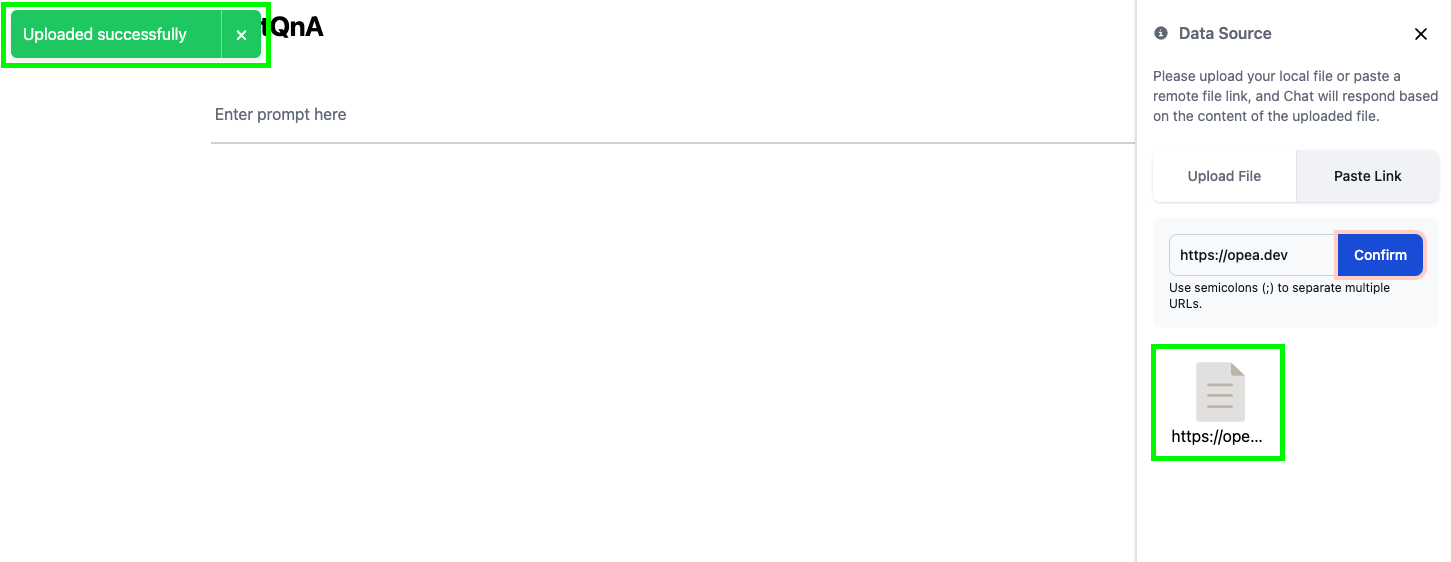
Ask “What is OPEA?” again to see the updated answer.

This time, the chatbot responds correctly based on the data it added to the prompt from the new source, the OPEA website.
Conclusion
In this task, you explored the foundational structure of a RAG application, covering how each component operates and interacts within the system. From question inference to answer generation, each part plays a critical role in OPEA’s RAG workflow, enhancing response relevance through retrieval and accurate language modeling. This hands-on session gives a glimpse into how OPEA utilizes RAG to streamline complex queries and elevate model accuracy through seamless integration across components
In the next Task, you’ll add guard rails to the chat bot. Guardrails are necessary to detect and mitigate bias, ensuring more responsible and fair responses from AI systems.