Explore OPEA ChatQnA deployment
Let’s now explore the OPEA ChatQnA RAG deployment. As mentioned, it’s a microservices blueprint designed for scalability, resilience, and flexibility. In this task you will explore each microservice, the purpose of exploring each microservice is to help you understand how each component contributes to the overall application. This learning path will guide you through the system, illustrating the role of each service and how they work together.
Each service can scale individually based on demand, optimizing resources and performance. Additionally, microservices improve fault isolation—if one service fails, it doesn’t disrupt the entire system. This architecture supports efficient maintenance, rapid updates, and adaptability, making it ideal for responding to changing business needs and user demands.
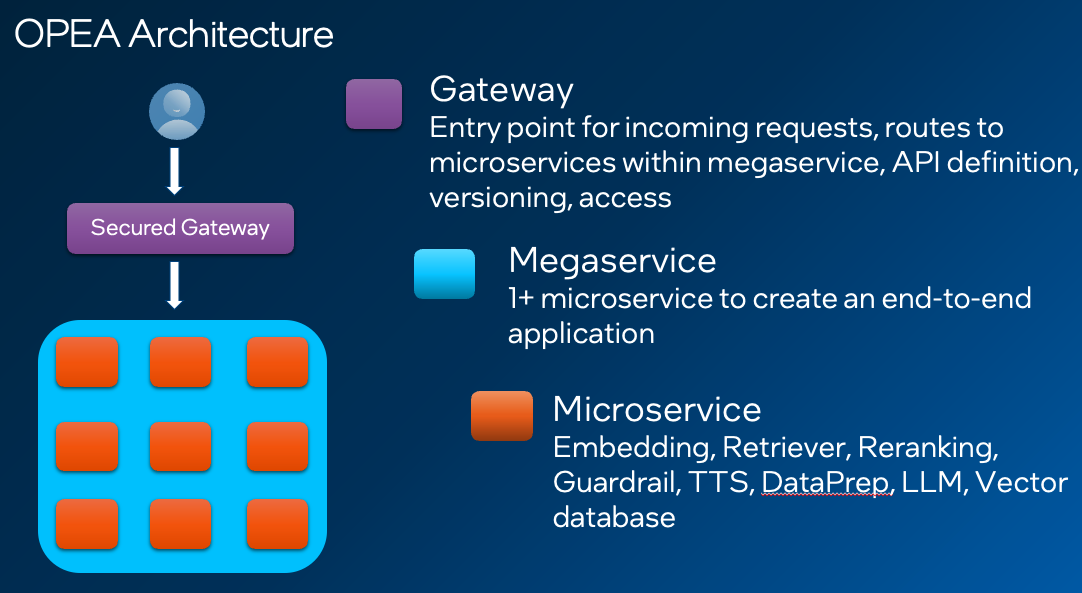
Every OPEA configuration is built on three main parts:
-
Megaservice : Microservice “orchestrator”. When deploying an end-to-end application with multiple parts involved, there is needed to specify how the flow will be within the microservices. You can learn more from OPEA documentation
-
Gateway : A gateway is the interface for users to access to the
megaserviceIt acts as the entry point for incoming requests, routing them to the appropriate Microservices within the megaservice architecture. -
Microservice : Each individual microservice part of the end-to-end application like : embeddings, retrievers, LLM and vector databases among others.
Before start exploring, consider that only the gateway and UI services are exposed externally. In this task, you’ll access each internal microservice directly to run tests, using the gateway (Nginx) to streamline access to these internal services.
You’ll need to take note of all pods deployed.
kubectl get svc lists all services in a Kubernetes cluster, showing their names, types, cluster IPs, and exposed ports. It provides an overview of how applications are exposed for internal or external access.
Run the following command on your CloudShell:
kubectl get svc
You will see output similar to this:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
chatqna ClusterIP XXX.XXX.XXX <none> 8888/TCP 12h
chatqna-chatqna-ui ClusterIP XXX.XXX.XXX <none> 5173/TCP 12h
chatqna-data-prep ClusterIP XXX.XXX.XXX <none> 6007/TCP 12h
chatqna-nginx NodePort XXX.XXX.XXX <none> 80:30167/TCP 12h
chatqna-redis-vector-db ClusterIP XXX.XXX.XXX <none> 6379/TCP,8001/TCP 12h
chatqna-retriever-usvc ClusterIP XXX.XXX.XXX <none> 7000/TCP 12h
chatqna-tei ClusterIP XXX.XXX.XXX <none> 80/TCP 12h
chatqna-teirerank ClusterIP XXX.XXX.XXX <none> 80/TCP 12h
chatqna-tgi ClusterIP XXX.XXX.XXX <none> 80/TCP 12h
kubernetes ClusterIP XXX.XXX.XXX <none> 443/TCP 15h
The command kubectl get svc is used to view the services in a Kubernetes cluster, which are like entry points for accessing your applications. Each service has a name (such as chatqna or chatqna-ui) that identifies it. Services can be exposed in different ways: for example, a ClusterIP service is only accessible within the cluster, while a NodePort service is accessible externally through a specific port on the node. The Cluster-IP is the internal address used by other parts of the system to reach the service. If the service were available from outside the cluster, you would see an External-IP, but in this case, it’s
Now, let’s explore the architecture.
Step 1 : Megaservice (Orchestrator) (POD:chatqna:8888)
The megaservice encapsulates the complete logic for the ChatQnA RAG application. This microservice is tasked with processing incoming requests and executing all the necessary internal operations to generate appropriate responses.
This service isn’t directly exposed, but you can access it directly from the LoadBalancer, which forwards the request.
- Look for the load balancer
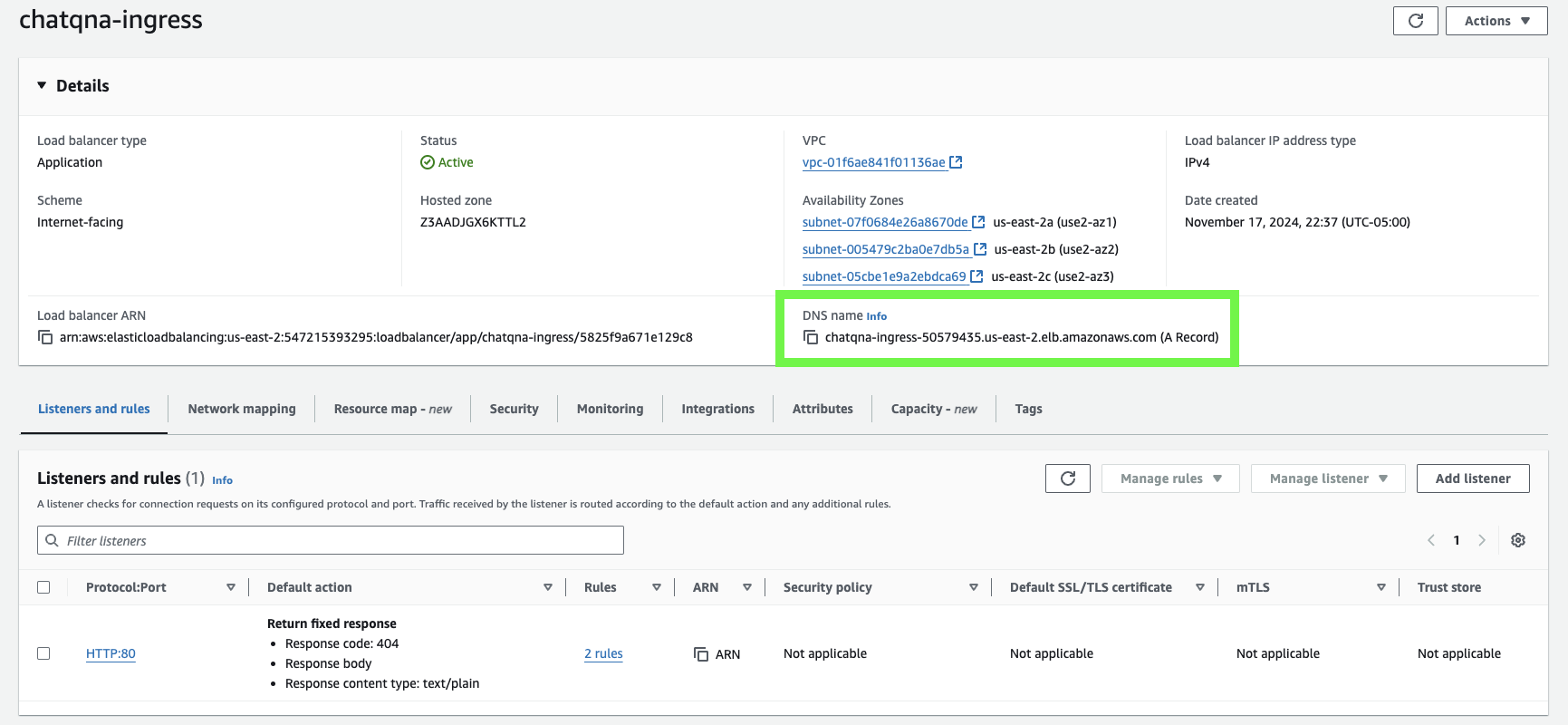
- Click on
chatqna-Ingress

- Note the
DNS Name.As mentioned, it’s the public URL that can be accessed externally.
You will use curl to send a request to an API endpoint to test the functionality of each microservice separately. The purpose is to ask a question, such as “What was the revenue of Nike in 2023?”, and verify that the API responds correctly. This helps ensure that all services are working as expected.
curl -X POST http://<**Chatqna-ingress Load Balancer DNS**>/v1/chatqna -H "Content-Type: application/json" -d '{"messages": [{"role": "user", "content": "What was the revenue of Nike in 2023?"}]}'
You should receive an answer back, verifying that all the services in the RAG flow are working.
You will see that the model couldn’t answer the question because it lacks the necessary context and operates on outdated information. Without up-to-date or relevant data, it’s unable to provide accurate responses. You’ll fix this in few minutes by using RAG to allow the model to pull in current, contextually relevant information, ensuring more precise and relevant answers.
Next, you’ll explore each microservice individually to examine its behavior and identify how each component can support the model in accurately answering the question.
Step 2 : Microservices
Each microservice follows the following logic performing a task within the RAG flow:
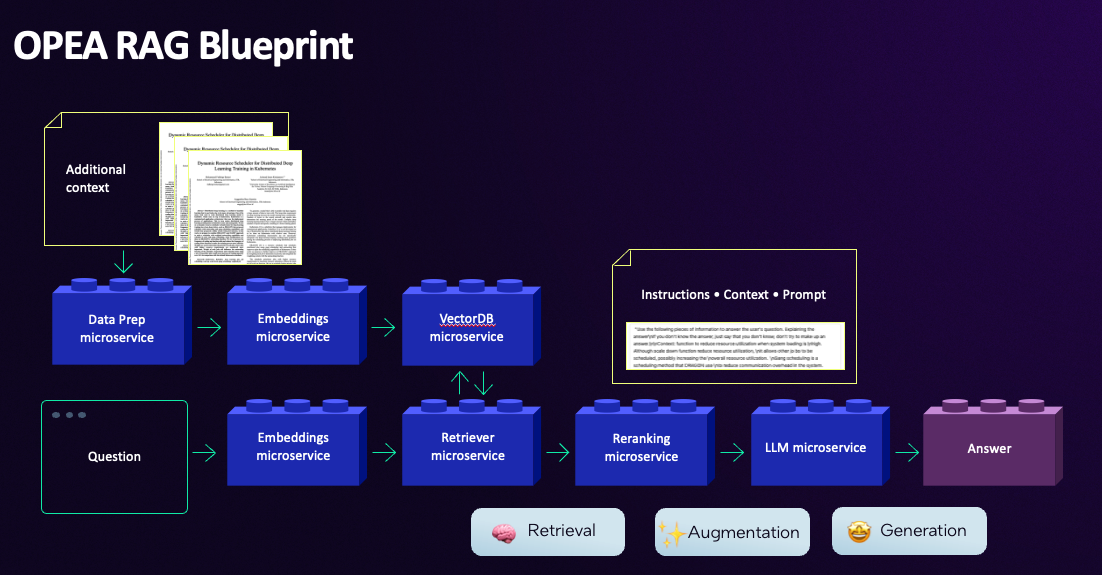
In the flow, you can observe the microservices and we can divide the RAG flow into two steps:
-
Preprompting: This step involves preparing the knowledge base (KB) by uploading relevant documents and ensuring that the information is organized for effective retrieval.
-
Prompting: This step focuses on retrieving the relevant data from the knowledge base and using it to generate an accurate answer to the user’s question.
Preprompting
In this step, the logic is to start from a document (Nike’s revenue PDF), and do the preprocessing needed to make it ready to be stored in a database. As shown, this process primarily involves 3 microservices: data preparation, embeddings and vector store. Let’s explore each microservice
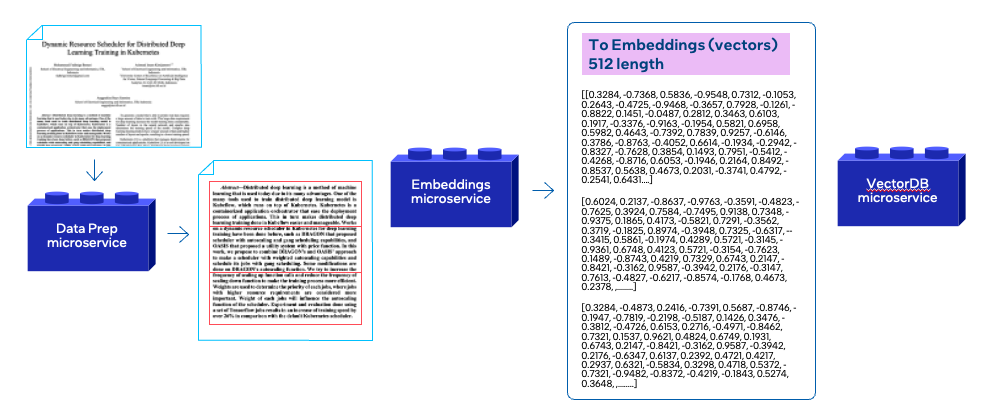
Embedding Microservice (POD:chatqna-tei:80)
An embedding is a numerical representation of an object—such as a word, phrase, or document in a continuous vector space. In the context of natural language processing (NLP), embeddings represent words, sentences, or other pieces of text as a set of numbers (or a “vector”) that capture their meaning, relationships, and context. By transforming text into this format, embeddings make it easier for machine learning models to understand and work with text data.
For example, the following image shows how word embeddings represent words as points in a vector space based on their relationships. Words with similar meanings, like “king” and “queen” are closer together, and the embedding model captures these connections through vector arithmetic.
During training, if the model sees “king” often used with “man” and “queen” with “woman,” it learns that “king” and “queen” relate similarly to “man” and “woman.” So, it positions these words in ways that reflect gender relationships in language.

Embeddings are a key component for RAG:
• Capturing Meaning: Embeddings represent the semantic relationships between words, allowing RAG models to understand context and nuances in language, enhancing their ability to generate relevant responses.
• Dimensionality Reduction: By converting complex information into fixed-size vectors, embeddings streamline data processing, making RAG systems more efficient and faster.
• Improving Model Performance: Embeddings enable RAG models to generalize better by leveraging semantic similarities, facilitating more accurate information retrieval, and improving the quality of generated content.
OPEA provides multiple options to run your embeddings microservice, as detailed in the OPEA embedding documentation:
In this case, ChatQnA uses Hugging Face TEI microservice running the embedding model BAAI/bge-large-en-v1.5 locally.
To explore the microservices that are not exposed, you will use the nginx pod to contact them via curl. To do that, the microservice will be accessed using each microservice’s internal DNS name. Above, you used the command kubectl get svc to list out all of the services; these are the services you will interact with.
- Access to ngnix POD (copy your NGNIX entire pod name from
kubectl get podsand REPLACE chatqna-nginx-xxxxxxxx on the below command)
kubectl exec -it <*POD name:chatqna-nginx-xxxxxxxx*> -- /bin/bash
Your command prompt should now indicate that you are inside the container, reflecting the change in environment:
root@chatqna-nginx-deployment-xxxxxxxxxxxx:/#
Once inside, you will now have direct access to the internal pods.
- Get the embedding from the Embeddings Microservice for the phrase “What was Deep Learning?”:
curl chatqna-tei:80/embed \
-X POST \
-d '{"inputs":"What was Deep Learning?"}' \
-H 'Content-Type: application/json'
The answer will be the vector representation of the phrase “What was Deep Learning?”. This service returns the vector embedding for the inputs from the REST API.

Vector Database Microservice (POD:chatqna-redis-vector-db:80)
The Vector Database microservice is a crucial component in the RAG application as it stores and retrieves embeddings. This is especially useful in applications like ChatQnA (RAG), where relevant information must be retrieved quickly based on the user’s query.
Using Redis as a Vector Database
In this Task, you use Redis as the vector database. You can find all of the supported alternatives in the OPEA vector store repository
A Vector Database (VDB) is a specialized database designed to store and manage high-dimensional vectors—numeric representations of data points like words, sentences, or images. In AI and machine learning, these vectors are typically embeddings, which capture the meaning and relationships of data in a format that algorithms can process efficiently, as we have shown before.
Data Preparation Microservice(POD:chatqna-data-prep:6007)
The Dataprep Microservice is responsible for preparing data in a digestible format for the application, converting it to embeddings, using the embedding microservice, and loading it to the database. This service preprocesses/transforms the data, making sure it is clean, organized, and suitable for further processing.
Specifically, this microservice receives data (such as documents), processes it by breaking it into chunks, sends it to the embedding microservice, and stores these vectors in the vector database. The microservice’s functionality may depend on the specific vector database being used, as each database has its own requirements for data formatting
To test it and help the model answer the initial question What was Nike revenue in 2023?, you will need to upload a context file (revenue report) to be processed.
Execute the following command to download a sample Nike revenue report to the nginx pod (if you are no longer logged in to the NGinx pod, be sure to use the above command to log in again):
- Download the document to the microservice :
curl -C - -O https://raw.githubusercontent.com/opea-project/GenAIComps/main/comps/third_parties/pathway/src/data/nke-10k-2023.pdf
- Feed the knowledge base (Vectord) with the document (It will take ~30 seconds):
curl -X POST "chatqna-data-prep:6007/v1/dataprep" \
-H "Content-Type: multipart/form-data" \
-F "files=@./nke-10k-2023.pdf"
After running the previous command, you should receive a confirmation message like the one below. This command updated the knowledge base by uploading a local file for processing.
{
"status": 200,
"message": "Data preparation succeeded"
}
The data preparation microservice API can retrieve information about the list of files stored in the vector database.
- Verify if the document was uploaded:
curl -X POST "chatqna-data-prep:6007/v1/dataprep/get_file" \
-H "Content-Type: application/json"
After running the previous command, you should receive the confirmation message.
{
"name": "nke-10k-2023.pdf",
"id": "nke-10k-2023.pdf",
"type":
"File",
"parent": ""
}
Congratulations! You’ve successfully prepared your knowledge base. Now you’ll explore the microservices involved in prompt handling.
Step 3: Prompting
Once the knowledge base is set up, you can begin interacting with the application by asking it context-specific questions. RAG plays a crucial role in ensuring the responses are accurate and grounded in relevant data.
The process starts with the application retrieving the most relevant information from the knowledge base in response to the user’s query. This step ensures the LLM has up-to-date and precise context to answer the user’s query.
Next, the retrieved information is combined with the input prompt that is sent to the Large Language Model (LLM). This enriched prompt allows the model to generate answers that are informed by both the external data and its pre-trained knowledge.
Finally, you will see how the LLM utilizes the enriched prompt to generate a coherent and contextually accurate response. By leveraging RAG, the application effectively delivers answers that are tailored to the user’s query, grounded in the most relevant and up-to-date information from the knowledge base.
The microservices involved in this stage are embeddings,vector db,retriever,reranking and finally the LLM
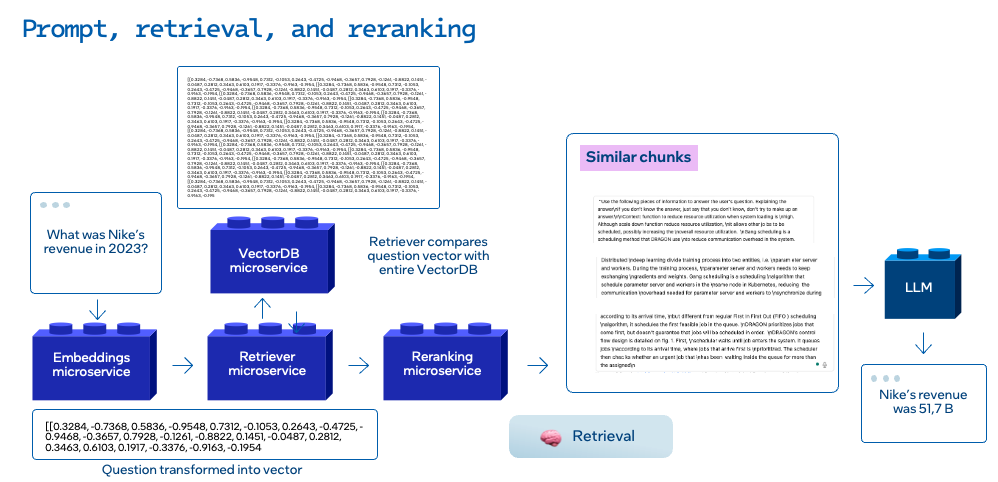
Retriever Microservice (POD:chatqna-retriever-usvc:7000)
The Retriever Microservice locates the most relevant information within the knowledge base and returns similar documents to the user’s question. It is designed to work with a number of back-end systems that store knowledge and provide APIs to retrieve data that (hopefully!) best matches the intent the user had when asking his or her question. Different knowledge bases provide different APIs for retrieving relevant information. Vector databases provide vector similarity for embeddings from the source documents and a vector embedding for the user’s question. Graph databases use graph locality to find matches. Relational databases use string and regular expression matching to find matches.
In this task, you use the Redis vector database and access the vector database through Redis retriever.
Of course, you need to have a vector embedding for the retrieval query. You can generate an embedding for the user’s question, “What was Nike revenue in 2023?”, to test the retriever against the Nike revenue information you loaded in the previous step.
To create the embedding, use the chatqna-tei microservice (again, make sure you are logged in to the NGinx pod).
- Create the embedding and save locally (embed_question):
embed_question=$(curl chatqna-tei:80/embed \
-X POST \
-d '{"inputs":"What was the Nike revenue in 2023?"}' \
-H 'Content-Type: application/json')
You should get the details about the writing task:
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 9571 100 9524 100 47 1097k 5543 --:--:-- --:--:-- --:--:-- 1168k
- Check to see if your embedding was saved:
echo $embed_question
You should be able to see the vectors the embeddings microservice generated. You are now able to use the retriever microservice to get the most similar information from your knowledge base.
- Get and save similar vectors from the initial
embed_questionlocallysimilar_docs:
similar_docs=$(curl chatqna-retriever-usvc:7000/v1/retrieval -X POST -d "{\"text\":\"test\",\"embedding\":${embed_question}}" -H 'Content-Type: application/json')
By looking at the previous output, you can see the most similar passages (TOP_3) from the document Nike revenue report and the question “What was the Nike revenue in 2023?”.
echo $similar_docs
The following output has been formatted for better readability. Your results will be presented in plain text and may vary slightly due to the similarity search algorithm. However, you can double check that the retrieved documents will be relevant to your initial query.
{
"id": "eb5a39b6f8b42b90fbf9ebc5f850ffd5",
"retrieved_docs": [{
"downstream_black_list": [],
"id": "329f5dad1bef1b809bf4be2c0a247c50",
"text": "believe will further accelerate our digital transformation. We believe this unified approach will accelerate growth and unlock more
efficiency for our business, while driving\nspeed and responsiveness as we serve consumers globally.\nFINANCIAL HIGHLIGHTS\n• In fiscal 2023,
NIKE, Inc. achieved record Revenues of $51.2 billion, which increased 10% and 16% on a reported and currency-neutral basis, respectively\n•
NIKE Direct revenues grew 14% from $18.7 billion in fiscal 2022 to $21.3 billion in fiscal 2023, and represented approximately 44% of total
NIKE Brand revenues for\nfiscal 2023\n• Gross margin for the fiscal year decreased 250 basis points to 43.5% primarily driven by higher product
costs, higher markdowns and unfavorable changes in foreign\ncurrency exchange rates, partially offset by strategic pricing actions\n• Inventories
as of May 31, 2023 were $8.5 billion, flat compared to the prior year, driven by the actions we took throughout fiscal 2023 to manage inventory
levels\n• We returned $7.5 billion to our shareholders in fiscal 2023 through share repurchases and dividends\n• Return on Invested Capital ("ROIC")
as of May 31, 2023 was 31.5% compared to 46.5% as of May 31, 2022. ROIC is considered a non-GAAP financial measure, see\n"Use of Non-GAAP
Financial Measures\" for further information.\nFor discussion related to the results of operations and changes in financial condition for fiscal
2022 compared to fiscal 2021 refer to Part II, Item 7. Management's"
},
{
"downstream_black_list": [],
"id": "0e9c24a90034370949f3fb7983cad321",
"text": "(INCL. HEDGES) SELLING PRICE\n(NET OF\nDISCOUNTS)*.Table of Contents\nFISCAL 2023 NIKE BRAND REVENUE HIGHLIGHTS\nThe following tables
present NIKE Brand revenues disaggregated by reportable operating segment, distribution channel and major product line:\nFISCAL 2023 COMPARED
TO FISCAL 2022\n• NIKE, Inc. Revenues were $51.2 billion in fiscal 2023, which increased 10% and 16% compared to fiscal 2022 on a reported
and currency-neutral basis, respectively.\nThe increase was due to higher revenues in North America, Europe, Middle East & Africa (\"EMEA\"),
APLA and Greater China, which contributed approximately 7, 6,\n2 and 1 percentage points to NIKE, Inc. Revenues, respectively.\n• NIKE Brand
revenues, which represented over 90% of NIKE, Inc. Revenues, increased 10% and 16% on a reported and currency-neutral basis, respectively.
This\nincrease was primarily due to higher revenues in Men's, the Jordan Brand, Women's and Kids' which grew 17%, 35%,11% and 10%, respectively,
on a wholesale\nequivalent basis.\n• NIKE Brand footwear revenues increased 20% on a currency-neutral basis, due to higher revenues in Men's,
the Jordan Brand, Women's and Kids'. Unit\nsales of footwear increased 13%, while higher average selling price (\"ASP\") per pair contributed
approximately 7 percentage points of footwear revenue\ngrowth. Higher ASP was primarily due to higher full-price ASP, net of discounts, on a
wholesale equivalent basis, and growth in the size of our NIKE Direct"
},
{
"downstream_black_list": [],
"id": "2b08a600209e1765339ff99c69966857",
"text": "RESULTS OF OPERATIONS\n(Dollars in millions, except per share data)\nFISCAL 2023\nFISCAL 2022\n% CHANGE\nFISCAL 2021\n% CHANGE
Revenues\n$51,217 \n$\n46,710 \n10 % $\n44,538 \n5 %\nCost of sales\n28,925 \n25,231 \n15 %\n24,576 \n3 %\nGross profit\n22,292 \n21,479 \n4 %
19,962 \n8 %\nGross margin\n43.5 %\n46.0 %\n44.8 %\nDemand creation expense\n4,060 \n3,850 \n5 %\n3,114 \n24 %\nOperating overhead expense
12,317 \n10,954 \n12 %\n9,911 \n11 %\nTotal selling and administrative expense\n16,377 \n14,804 \n11 %\n13,025 \n14 %\n% of revenues 32.0 %\n31.7
%\n29.2 %\nInterest expense (income), net\n(6)\n205 \n— \n262 \n— \nOther (income) expense, net\n(280)\n(181)\n— \n14 \n— \nIncome before income
taxes\n6,201 \n6,651 \n-7 %\n6,661 \n0 %\nIncome tax expense\n1,131 \n605 \n87 %\n934 \n-35 %\nEffective tax rate\n18.2 %\n9.1 %\n14.0 %\nNET
INCOME\n$\n5,070 \n$\n6,046 \n-16 % $\n5,727 \n6 %\nDiluted earnings per common share\n$\n3.23 \n$\n3.75 \n-14 % $\n3.56 \n5 %\n2023 FORM 10-K 31.
Table of Contents\nCONSOLIDATED OPERATING RESULTS\nREVENUES\n(Dollars in millions)\nFISCAL\n2023\nFISCAL\n2022\n% CHANGE\n% CHANGE\nEXCLUDING
CURRENCY\nCHANGES\nFISCAL\n2021\n% CHANGE\n% CHANGE\nEXCLUDING\nCURRENCY\nCHANGES\nNIKE, Inc. Revenues:\nNIKE Brand Revenues by:\nFootwear\n$
33,135 $\n29,143 \n14 %\n20 % $\n28,021 \n4 %\n4 %\nApparel\n13,843 \n13,567 \n2 %\n8 %\n12,865 \n5 %\n6 %\nEquipment\n1,727 \n1,624 \n6 %\n13
%\n1,382 \n18 %\n18 %\nGlobal Brand Divisions\n58 \n102 \n-43 %\n-43 %\n25 \n308 %\n302 %\nTotal NIKE Brand Revenues\n$\n48,763 $\n44,436 \n10
%\n16 % $\n42,293 \n5 %\n6 %\nConverse\n2,427 \n2,346 \n3 %\n8 %\n2,205 \n6 %\n7 %\nCorporate\n27"
}
The application will use that information as context for prompting the LLM, but there is still one more step that you need to do to refine and check the quality of those retrieved documents: the reranker.
Reranker Microservice (POD:chatqna-teirerank:80)
The Reranking Microservice, fueled by reranking models, is a straightforward yet immensely potent tool for semantic search. When provided with a query and a collection of documents, reranking swiftly reorders the documents based on their semantic relevance to the query, arranging them from most to least pertinent. This microservice significantly enhances overall accuracy. You will commonly use either a dense embedding model or a sparse lexical search index in a text retrieval system to retrieve relevant text documents based on the user’s input. A reranking model improves the results by rearranging potential candidates into a final, optimized order.
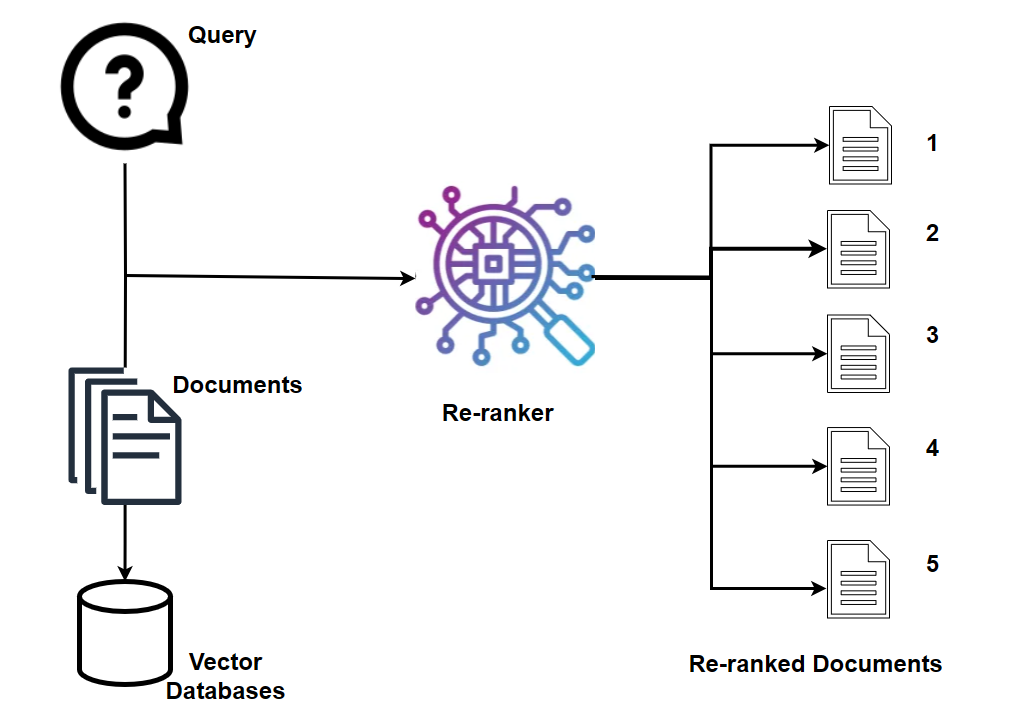
OPEA has multiple options for re-rankers. For this lab, you’ll use the Hugging Face TEI for re-ranking. It is the chatqna-teirerank microservice in your cluster.
The reranker will use similar_docs from the previous stage and compare it with the question What was Nike Revenue in 2023? to check the quality of the retrieved documents.
Extract the 3 retrieved text snippets and save them in a new variable to be reranked:
- Install jq dependencies to format
similar_docs
echo -e "deb http://deb.debian.org/debian bookworm main contrib non-free\ndeb http://security.debian.org/debian-security bookworm-security main contrib non-free\ndeb http://deb.debian.org/debian bookworm-updates main contrib non-free" > /etc/apt/sources.list && apt update && apt install -y jq
- Extract and format the texts into a valid JSON array of strings
texts=$(echo "$similar_docs" | jq -r '[.retrieved_docs[].text | @json]')
- Send the request to the microservice with the query and the formatted texts:
curl -X POST chatqna-teirerank:80/rerank \
-d "{\"query\":\"What was Nike Revenue in 2023?\", \"texts\": $texts}" \
-H 'Content-Type: application/json'
Response:
The following output has been formatted for better readability. Your results are displayed in plain text and may vary slightly due to the similarity search algorithm. The retrieved documents are ranked by similarity to your query, with the highest-ranked index representing the most relevant match. You can confirm that the top-ranked document corresponds to the one most closely aligned with your query.
{
"index": 2,
"score": 0.9972289
},
{
"index": 0,
"score": 0.9776342}
},
{
"index": 3,
"score": 0.9296986
},
{
"index": 1,
"score": 0.84730965
}
The server responds with a JSON array containing objects with two fields: index and score. This indicates how the snippets are ranked based on their relevance to the query: {"index":2,"score":0.9972289} means the first text (index 0) has a high relevance score of approximately 0.7982.
{"index":0,"score":0.9776342},{"index":3,"score":0.9296986},{"index":1,"score":0.84730965} indicates that the other snippets (index 3,1 and 2) have a much lower score.
As you can see from similar_doc the id=2 has the below information where it EXACTLY refers to the revenue for 2023!
"text": "RESULTS OF OPERATIONS\n(Dollars in millions, except per share data)\nFISCAL 2023\nFISCAL 2022\n% CHANGE\nFISCAL 2021\n% CHANGE
Revenues\n$51,217 \n$\n46,710 \n10 % $\n44,538 \n5 %\nCost of sales\n28,925 \n25,231 \n15 %\n24,576 \n3 %\nGross profit\n22,292 \n21,479 \n4 %
19,962 \n8 %\nGross margin\n43.5 %\n46.0 %\n44.8 %\nDemand creation expense\n4,060 \n3,850 \n5 %\n3,114 \n24 %\nOperating overhead expense
12,317 \n10,954 \n12 %\n9,911 \n11 %\nTotal selling and administrative expense\n16,377 \n14,804 \n11 %\n13,025 \n14 %\n% of revenues 32.0 %\n31.7
%\n29.2 %\nInterest expense (income), net\n(6)\n205 \n— \n262 \n— \nOther (income) expense, net\n(280)\n(181)\n— \n14 \n— \nIncome before income
taxes\n6,201 \n6,651 \n-7 %\n6,661 \n0 %\nIncome tax expense\n1,131 \n605 \n87 %\n934 \n-35 %\nEffective tax rate\n18.2 %\n9.1 %\n14.0 %\nNET
INCOME\n$\n5,070 \n$\n6,046 \n-16 % $\n5,727 \n6 %\nDiluted earnings per common share\n$\n3.23 \n$\n3.75 \n-14 % $\n3.56 \n5 %\n2023 FORM 10-K 31.
Table of Contents\nCONSOLIDATED OPERATING RESULTS\nREVENUES\n(Dollars in millions)\nFISCAL\n2023\nFISCAL\n2022\n% CHANGE\n% CHANGE\nEXCLUDING
CURRENCY\nCHANGES\nFISCAL\n2021\n% CHANGE\n% CHANGE\nEXCLUDING\nCURRENCY\nCHANGES\nNIKE, Inc. Revenues:\nNIKE Brand Revenues by:\nFootwear\n$
33,135 $\n29,143 \n14 %\n20 % $\n28,021 \n4 %\n4 %\nApparel\n13,843 \n13,567 \n2 %\n8 %\n12,865 \n5 %\n6 %\nEquipment\n1,727 \n1,624 \n6 %\n13
%\n1,382 \n18 %\n18 %\nGlobal Brand Divisions\n58 \n102 \n-43 %\n-43 %\n25 \n308 %\n302 %\nTotal NIKE Brand Revenues\n$\n48,763 $\n44,436 \n10
%\n16 % $\n42,293 \n5 %\n6 %\nConverse\n2,427 \n2,346 \n3 %\n8 %\n2,205 \n6 %\n7 %\nCorporate\n27"
Just the first will be used to prompt the LLM.
LLM microservice (POD:chatqna-tgi:80)
The heart of the RAG application is the Large Language Model (LLM), which is the primary focus of your efforts. As mentioned in the introduction, you leverage RAG to enhance LLM performance.
LLM offerings can generally be divided into two main categories: closed models and open source models that you can run locally. Each type has its own advantages and disadvantages. This microservice architecture provides the flexibility to choose between these models, accommodating a variety of LLMs that can be broadly classified as either closed or open source.
-
Closed Models: These are proprietary models developed by major companies with significant infrastructure and resources, such as Amazon Web Services, OpenAI, and Google. Closed models typically offer high-quality, reliable outputs optimized through large-scale training on diverse datasets. However, they can have limitations in customization and may incur higher costs. Additionally, they require API access, which can restrict data sovereignty and limit usage for applications with strict data governance requirements.
-
Open Source Models: These models are freely available. You can customize them to a high degree, enabling you to control the model’s performance and adaptability to specific tasks. Running open source models locally or on private cloud infrastructure enhances data privacy and cost-effectiveness. However, you may need more technical expertise to run open source models to tune them optimally and larger computational resources to perform comparably to their closed counterparts.
OPEA allows the integration of any option. In this example, we have used the TGI for Hugging Faces.
For test purposes, you can directly prompt the TGI(LLM) to see if the model can answer to the initial question What was Nike revenue in 2023?
- Directly prompt the TGI(LLM) Microservice:
curl chatqna-tgi:80/generate \
-X POST \
-d '{"inputs":"What was Nike revenue in 2023?","parameters":{"max_new_tokens":200, "do_sample": true}}' \
-H 'Content-Type: application/json'
The model will give you the answer to the prompt like the following:
"generated_text":" Nike revenue in 2023 has not been reported as it is still in the fourth quarter. The previous full financial year—which is 2022—brought in $48.9 billion in revenue for the American multinational sportswear company. They deal with the design, development, manufacturing, and worldwide marketing/sales of a diverse portfolio of products. From coming into being in 1964 as Blue Ribbon Sports, the firm was renamed Nike, Inc., in 1978. Jumpman logos (for example), include Michael Jordan, who is a former professional basketball player—are among the brands' numerous trademarked symbols, tied to the 'Swoosh' logo.\n\nNike revenues are clearly affected by the football World Cup. Consequently, for the 13 weeks ending January 29 in 2022, which were characterized by the football world cup
This directly prompts the LLM without providing the context. We can see that the model actually gives the wrong answer. To check the overall RAG performance, we should test with the megaservice as we did at the beginning of this task, which will involve the entire flow.
- Exit the ngnix POD: You may find “pending jobs”, please ignore it and try again.
root@chatqna-nginx-deployment-XXXXXXXXXXXX:/# exit
Use the load balancer URL you saved above in the below command to send the question “What was Nike’s revenue in 2023?” to the ChatQNA application.
- Run the curl to the load balancer again:
curl http://<REPLACE**Chatqna-ingress Load Balancer DNS**>/v1/chatqna \
-H "Content-Type: application/json" \
-d '{"messages": "What was the revenue of Nike in 2023?"}'
- Check your results. You will notice the streaming response, which is normal behavior for the microservice as it streams the answer. A streaming response means the data is sent in smaller chunks as it becomes available rather than all at once. In the application, this response is received by the UI and converted into a readable format, allowing the user to view the data as it arrives in real time.
data: b' The'
data: b’ revenue'
data: b’ of'
data: b’ N'
data: b’I'
data: b’KE'
data: b’,'
data: b’ Inc'
data: b’.'
data: b’ in'
data: b’ fiscal'
data: b’ '
data: b'2'
data: b'0'
data: b'2'
data: b'3'
data: b’ ('
data: b’as'
data: b’ of'
data: b’ May'
data: b’ '
data: b'2'
data: b'0'
data: b'2'
data: b'3'
data: b’)'
data: b’ is'
data: b’ $'
data: b'5'
data: b'1'
data: b’,'
data: b'2'
data: b'1'
data: b'7'
data: b’ million'
data: b’.'
data: b’ This'
data: b’ information'
data: b’ is'
data: b’ based'
data: b’ on'
data: b’ the'
data: b’ consolid'
data: b’ated'
data: b’ operating'
data: b’ results'
data: b’ provided'
data: b’ in'
data: b’ their'
data: b’ financial'
data: b’ reports'
data: b’.'
data: b''
data: b''
In this section, you’ve gained insights into each component involved in a RAG application, including the megaservice, gateway, and individual microservices. By testing each microservice in the console, you’ve explored their functionalities and interactions within the overall architecture.
This hands-on experience allows you to understand how each component contributes to the retrieval-augmented generation process. You’ve observed how the pre-prompting phase prepares the knowledge base by uploading and organizing relevant documents, while the prompting phase retrieves this information to generate accurate responses.